Thứ Ba, 26 tháng 1, 2021
Thứ Ba, 20 tháng 8, 2019
Mô hình IPA mức độ quan trọng – mức độ thực hiện (IPA – Importance-Performance Analysis)
Nhóm MBA giới thiệu mô hình IPA khi làm luận văn,cách thiết kế bảng câu hỏi IPA. Song song đó là cách đánh giá khi biểu diễn sơ đồ IPA trên đồ thị.
Mô hình IPA mức độ quan trọng – mức độ thực hiện (IPA – Importance-Performance Analysis) là gì?
Mô hình IPA mức độ quan trọng – mức độ thực hiện (IPA – Importance-Performance Analysis) được đề xuất bởi Martilla và Jame năm 1977. Mô hình IPA là mô hình đo lường chất lượng dịch vụ dựa vào sự khác biệt giữa ý kiến khách hàng về mức độ quan trọng của các chỉ tiêu và mức độ thực hiện các chỉ tiêu của nhà cung ứng dịch vụ (I-P gaps). Mô hình này phân loại những thuộc tính đo lường chất lượng dịch vụ, cung cấp cho nhà cung ứng dịch vụ những thông tin bổ ích về điểm mạnh và điểm yếu của những dịch vụ mà mình cung cấp cho khách hàng. IPA giúp doanh nghiệp xác định tầm quan trọng của chỉ tiêu dịch vụ cũng như điểm mạnh, điểm yếu của sản phẩm/ dịch vụ cung cấp trên thị trường.
Cụ thể, quá trình phát triển IPA được thực hiện bằng cách so sánh hai tiêu chuẩn hình thành nên quyết định lựa chọn khách hàng, cụ thể: (1) Tầm quan trọng tương đối của các thuộc tính chất lượng và (2) Mức độ thực hiện các thuộc tính chất lượng. Theo Barsky (1995), mức độ quan trọng thấp nhất của thuộc tính chỉ ra khả năng ít làm ảnh hưởng tới nhận thức chung về CLDV. Ngược lại, thuộc tính có mức độ quan trọng cao thì sẽ ảnh hưởng lớn nhận thức của họ. Mô hình này phân loại những thuộc tính đo lường chất lượng dịch vụ, cung cấp cho nhà cung ứng dịch vụ những thông tin bổ ích về điểm mạnh và điểm yếu của những dịch vụ mà chính họ cung cấp cho khách hàng. Từ đó, nhà quản trị cung ứng dịch vụ sẽ có những quyết định chiến lược đúng đắn để nâng cao chất lượng dịch vụ.
Bảng câu hỏi cho mô hình IPA được thiết kế như thế nào?
Bảng câu hỏi lúc nào cũng có hai phần trả lời cho cùng một câu hỏi. Đó là phần trả lời về mức độ quan trọng Importance, và phần trả lời mức độ thực hiện Performance.

Ma trận IPA là gì?
Mỗi ma trận IPA gồm 4 phần tư với trục tung (Y) thể hiện mức độ quan trọng và trục hoành (X) thể hiện mức độ thực hiện như sơ đồ sau:

- Phần tư thứ 1 (Tập trung phát triển): Mức độ quan trọng cao , mức độ thực hiện thấp. Những thuộc tính nằm ở phần tư này được xem là rất quan trọng đối với khách hàng, nhưng mức độ thực hiện của nhà cung ứng dịch vụ rất kém. Kết quả này giúp cho nhà quản trị cung ứng dịch vụ du lịch chú ý những thuộc tính này, tập trung phát triển mức độ cung ứng dịch vụ nhằm thỏa mãn khách hàng.
- Phần tư thứ 2 (Tiếp tục duy trì): Mức độ quan trọng cao, mức độ thực hiện cao. Những thuộc tính nằm ở phần tư này được xem là rất quan trọng đối với khách hàng và nhà cung ứng dịch vụ cũng đã có mức độ thể hiện rất tốt. Nhà quản trị cung ứng dịch vụ nên tiếp tục duy trì và phát huy thế mạnh này.
- Phần tư thứ 3 (Hạn chế phát triển): Mức độ quan trọng thấp, mức độ thực hiện thấp. Những thuộc tính nằm ở phần tư này được xem là có mức độ thể hiện thấp và không quan trọng đối với khách hàng. Nhà quản trị cung ứng dịch vụ nên hạn chế nguồn lực phát triển những thuộc tính này.
- Phần tư thứ 4 (Giảm sự đầu tư): Mức độ quan trọng thấp, mức độ thực hiện cao. Những thuộc tính nằm ở phần tư này được xem là không quan trọng đối với khách hàng, nhưng mức độ thể hiện của nhà cung ứng rất tốt. Có thể xem sự đầu tư quá mức như hiện tại là vô ích. Nhà quản trị cung ứng dịch vụ nên sử dụng nguồn lực này tập trung phát triển những thuộc tính khác.
Cụ thể hơn: mối quan hệ giữa mức độ quan trọng (I) và mức độ thực hiện (P) các thuộc tính của điểm đến được thể hiện thông qua hiệu số (P – I). Nếu (P – I) ≥ 0 cho thấy chất lượng dịch vụ tốt và ngược lại cho thấy chất lượng dịch vụ không tốt khi (P – I) < 0.
Hiệu số Chất lượng dịch vụ
P – I >= 0 Tốt
P – I < 0 Không tốt
Lý do lựa chọn mô hình ipa
SERVQUAL và SERVPERF chỉ đo mức độ hài lòng mà không bao gồm xếp hạng tầm quan trọng của các thuộc tính. SERVQUAL cũng có nhiều hạn chế, đó là phải thu thập thông tin trước và sau khi khách hàng sử dụng dịch vụ. SERVPERF không biết đặc điểm nào của dịch vụ được khách hàng kỳ vọng cao. IPA là vượt trội hơn so cả SERVPERF và SERVQUAL vì nó có đánh giá tầm quan trọng của các thuộc tính. Hơn nữa, IPA có thể được vẽ đồ họa bằng cách sử dụng tầm quan trọng và mức độ thực hiện cho mỗi thuộc tính. Với nhiều ưu điểm, mô hình IPA được nhiều nhà nghiên cứu sử dụng để đánh giá CLDV và để đề xuất giải pháp nâng cao CLDV một cách hiệu quả.
Không giống như mô hình SERVQUAL hay SERVPERF đánh giá giá trị tuyệt đối mức độ cảm nhận của người tiêu dùng về chất lượng dịch vụ, mô hình IPA được sử dụng để xác định mức độ quan trọng của từng tiêu chí chất lượng dịch vụ đối với người tiêu dùng.
Quy trình nghiên cứu định lượng đối với luận văn sử dụng mô hình IPA
- Khảo sát
- Làm sạch và mã hóa dữ liệu
- Phân tích dữ liệu:
+ Thống kê mô tả (thông tin mẫu, tính trị trung bình)
+ Đánh giá độ tin cậy của thang đo
+ Phân tích nhân tố cho mức độ quan trọng.
+ Paired Samples t-test (Kiểm dịnh sự khác biệt)
+ Biểu diễn lên mô hình IPA
+ Đề xuất, kiến nghị, giải pháp...
Như vậy, nhóm MBA Bách Khoa đã giới thiệu các khái niệm liên quan đến mô hình IPA và cách lập bảng câu hỏi cho nó. Các bạn có thể nhờ nhóm hỗ trợ thêm về các vấn đề trong bài luận văn về mã hóa, xử lý số liệu tốt nhé…
Liên hệ nhóm thạc sĩ Hỗ trợ SPSS.
– SMS, Zalo, Viber:

– Chat Facebook: http://facebook.com/hoidapSPSS/
– Email: hotrospss@gmail.com
Cách mã hóa bảng khảo sát và nhập dữ liệu từ bảng khảo sát vào Excel, vào SPSS
Sau khi thu thập dữ liệu bằng bảng khảo sát, thì bước tiếp theo là cần mã hóa dữ liệu theo định dạng của SPSS để SPSS có thể đọc dữ liệu và xử lý được. Nhóm MBA sẽ hướng dẫn các bạn cách nhập dữ liệu và mã hóa từ bảng khảo sát vào excel và SPSS nhé.
Nguyên tắc cơ bản:
1. Dòng đầu tiên của file excel là tên biến
2. Dòng thứ nhì của file excel là dữ liệu của người trả lời thứ 1
3. Dòng thứ ba của file excel là dữ liệu của người trả lời thứ 2
4. Tương tự cho các dòng tiếp theo.
Ví dụ bảng khảo sát được thu về như sau:

Thì việc đầu tiên để nhập bảng khảo sát vào excel là ta tạo file excel để lưu số liệu này, sau đó mã hóa các tên biến như phần tô vàng sau:

Tiếp tục đánh phiếu khảo sát như phân tô đỏ. Như biến GIOITINH đánh 1 bởi vì người trả lời chọn NAM trong phần giới tính. Giả sử họ chọn NỮ thì mình đánh 2 nhé. Lưu ý 1 hay 2 ở đây là theo thứ tự bố trí câu trả lời, chứ không phải phân biệt giới tính, cho Nam là số 1, Nữ xếp thứ 2 nhé.
Tương tự phần độ tuổi, cũng sẽ mã hóa làm 1 2 3 4. Tùy và người ta chọn mức tuổi nào thì sẽ đánh vào tương ứng trong excel.
Tiếp tục đến phần thang đo likert. Cũng có 5 mức độ nhé.
Cứ tiếp tục như vậy là xong phiếu của người trả lời đầu tiên. Đến người thứ 2, 3, 4... thì cứ tiếp tục cho mỗi người 1 dòng. Như vậy đã mã hóa xong và nhập xong số liệu từ bảng khảo sát vào excel . Còn muốn đưa từ excel vào spss thì các bạn xem bài này nhé http://phantichspss.com/cach-mo-file-spss-cach-luu-file-spss-cach-nhap-du-lieu-tu-excel-vao-spss.html
Như vậy, nhóm MBA Bách Khoa đã giới thiệu các thao tác cơ bản nhất cho người bắt đầu học SPSS về nhập và mã hóa bảng khảo sát vào excel. Các bạn có thể nhờ nhóm hỗ trợ thêm về các vấn đề trong bài luận văn về mã hóa, xử lý số liệu tốt nhé…
Liên hệ nhóm thạc sĩ Hỗ trợ SPSS.
– SMS, Zalo, Viber:
– Chat Facebook: http://facebook.com/hoidapSPSS/
– Email: hotrospss@gmail.com
Các loại thang đo trong SPSS Scale, Ordinal, Nominal
Ba dạng thang đo trong SPSS
Trong SPSS dữ liệu được đo lường measure qua 3 dạng thang đo như hình sau:
Đó là Scale, Ordinal, Nominal. Tuy nhiên để quy về bản chất có 4 loại như sau:
Nhóm MBA Bách Khoa sẽ giải thích chi tiết từng loại thang đo nhé.


Tùy theo tính chất của dữ liệu mà ta sẽ gán loại thang đo nào dữ liệu đó. Có hai loại dữ liệu là:
- Dữ liệu định tính .
- Dữ liệu định lượng.
Dữ liệu định tính ví dụ như Địa điểm: TP.HCM, Hà Nội, Lâm Đồng. Dữ liệu định lượng ví dụ như độ tuổi: 18, 19, 20, 30 tuổi.
-Dữ liệu định tính: bao gồm thang đo định danh Nominal, thang đo thứ bậc Ordinal
-Dữ liệu định lượng:gọi chung là Scale, bao gồm thang đo khoảng Interval, thang đo tỉ lệ Ratio
Chi tiết 4 loại thang đo
-Định danh (Nominal): Là loại thang đo dùng cho các đặc điểm thuộc tính, dùng để phân loại đối tượng. Khi thống kê người ta thường sử dụng các mã số để qui ước, giữa các con số này không có quan hệ hơn kém và không ý nghĩa toán học. Trong thang đo này các con số chỉ dùng để phân loại các đối tượng, chúng không mang ý nghĩa nào khác. Về thực chất thang đo danh nghĩa là sự phân loại và đặt tên cho các biểu hiện và ấn định cho chúng một ký số tương ứng. Ví dụ: Giới tính: 1: nữ; 2: nam.
-Thứ bậc (Ordinal): Là loại thang đo dùng cho các đặc điểm thuộc tính, các giá trị được sắp xếp theo trật tự tăng hoặc giảm dần và có mối quan hệ thứ bậc hơn kém. Thực chất thang đo thứ bậc là thang đo định danh các giá trị được sắp xếp theo thứ bậc. Lúc này các con số ở thang đo danh nghĩa được sắp xếp theo 1 quy ước nào đó về thứ bậc hay sự hơn kém, nhưng ta không biết được khoảng cách giữa chúng. Điều này có nghĩa là bất cứ thang đo thứ bậc nào cũng là thang đo định danh nhưng điều ngược lại thì chưa chắc đúng. Ví dụ: Học lực: 1. Yếu, kém 2. Trung bình 3. Khá 4. Giỏi 5. Xuất sắc
-Khoảng cách (Interval): Là loại thang đo dùng cho các đặc điểm số lượng, là thang đo thứ bậc có các khoảng cách đều nhau và liên tục. Dãy số này có hai cực ở hai đầu dãy số thể hiện hai trạng thái đối nghịch nhau. Dữ liệu tính toán cộng trừ có ý nghĩa. Đây là một dạng đặc biệt của thang đo thứ bậc vì nó cho biết được khoảng cách giữa các thứ bậc. Thông thường thang đo khoảng có dạng là một dãy các chữ số liên tục và đều đặn từ 1 đến 5, từ 1 đến 7 hay từ 1 đến 10. Dãy số này có 2 cực ở 2 đầu thể hiện 2 trạng thái đối nghịch nhau. Ví dụ: 1: hoàn toàn không đồng ý; 2: không đồng ý; 3: bình thường; 4: đồng ý; 5: hoàn toàn đồng ý.
-Tỉ lệ (Ratio): Là loại thang đo dùng cho đặc tính số lượng. Thang đo tỉ lệ có đầy đủ đặc tính của thang đo khoảng cách. Ngoài ra nó cho phép lấy tỉ lệ so sánh giữa hai giá trị của biến số . Dữ liệu tính toán tất cả đều có ý nghĩa. Ví dụ: - Tuổi của anh/chị: tuổi. Anh/chị đã vay ngân hàng bao nhiêu tiền: VNĐ
Chú ý: Sự khác nhau giữa thang đo khoảng và thang đo tỉ lệ:
-Ta có thể thực hiện được phép toán chia để tính tỉ lệ nhằm mục đích so sánh. Ví dụ: 1 người 50 tuổi thì có tuổi lớn gấp đôi người 25 tuổi
-Trong thang đo khoảng sự so sánh về mặt tỉ lệ giữa các giá trị không có ý nghĩa
Trong xử lý SPSS thường gộp chung thang đo khoảng cách và thang đo tỉ lệ thành thang đo định lượng (Scale).
Lưu ý là cho dù các thang đo likert được nhập vào excel, và excel lại đưa vào SPSS thì thường sẽ ra thang đo định tính Nominal, đúng ra ta cần đổi lại là Scale cho chính xác nhất. Nhưng không đổi vẫn không ảnh hưởng đến kết quả các bạn nhé.
Các bạn có thể nhờ nhóm hỗ trợ thêm về các vấn đề trong bài luận văn về mã hóa, xử lý số liệu tốt nhé…
Liên hệ nhóm thạc sĩ Hỗ trợ SPSS.
– SMS, Zalo, Viber:
– Chat Facebook: http://facebook.com/hoidapSPSS/
– Email: hotrospss@gmail.com
Split file để chia bộ dữ liệu thành nhiều phần khác nhau
Đặt vấn đề: làm sao để chia bộ dữ liệu thành nhiều phần khác nhau?
Bạn có file SPSS http://phantichspss.com/filefordownload/select-case-phantichspss.sav có 200 người trả lời, trong có dữ liệu Giới tính, Độ tuổi. Giờ bạn cần thực hiện thống kê tần số cho biến Độ tuổi, nhưng đánh giá cho Nam riêng, Nữ riêng thì sẽ làm cách nào? Giải pháp là dùng chức năng Split File nhé. Chức năng Split file này chia tập tin SPSS thành nhiều phần nhỏ khác nhau theo một tiêu chí nào đó. Từ đó khi chạy các thống kê liên quan nó sẽ ra các phần kết quả khác nhau. Ví dụ khi chia file thành Nam/Nữ riêng, và thực hiện chạy hồi quy 1 lần. Thì kết quả sẽ ra được hai bảng hồi quy( một bảng cho đối tượng Nam, một bảng cho đối tượng Nữ) các bạn nhé.
Phân bổ tần số GIỚI TÍNH và ĐỘ TUỔI như bên dưới

Giờ bạn muốn chạy thống kê tần số về ĐỘ TUỔI trên những người có giới tính Nam riêng, Nữ riêng
Cách thực hiện Split File trên SPSS
Bước 1: vào menu Data – Split File
Bước 2: chọn mục Organize output by groups,đưa biến GIOITINH qua, xong bấm OK


Ta thực hiện chạy thống kê tần số lại, kết quả cho thấy kết quả thống kê đã được chia làm 2 phần rõ rệt, GIOITINH=Nam( được tô màu đỏ) và GIOITINH=Nữ ( được tô màu xanh) như hình dưới.

Như vậy ta đã dùng chức năng Split File nhằm tách dữ liệu để thực hiện việc thống kê. Lưu ý là các bạn nhớ bỏ chọn Split File bằng cách chọn lại tất cả các cases(Vào menu Data – Split File- Chọn Analyze all cases, do not create groups – xong bấm OK) khi không có nhu cầu sử dụng chia dữ liệu, hoặc đơn giản nhất là tắt file spss mở lại là dữ liệu sẽ được chọn tất cả như ban đầu nhé.
Các bạn có thể nhờ nhóm hỗ trợ thêm về các vấn đề trong bài luận văn về mã hóa, xử lý số liệu tốt nhé…
Liên hệ nhóm thạc sĩ Hỗ trợ SPSS.
– SMS, Zalo, Viber:
– Chat Facebook: http://facebook.com/hoidapSPSS/
– Email: hotrospss@gmail.com
Chức năng lựa chọn dữ liệu select cases , cách lựa chọn dữ liệu thỏa điều kiện để chạy SPSS
Đặt vấn đề
Giả sử bạn có file spss có 200 người trả lời, giờ bạn cần lọc ra một số ít người trong 200 người đó thỏa một điều kiện cho trước nào đó, thì sẽ làm như thế nào? Giải pháp là dùng chức năng select cases nhé
Ví dụ các bạn có thể tải ở http://phantichspss.com/filefordownload/select-case-phantichspss.sav
Phân bổ tần số GIỚI TÍNH và ĐỘ TUỔI như bên dưới

Giờ bạn chỉ muốn chạy thống kê tần số về ĐỘ TUỔI trên những người có giới tính Nam, còn giới tính Nữ không chạy( ở đây mình chọn Nam, không chọn Nữ dể ví dụ thôi, chứ không phải phân biệt giới tính nha) . Vậy các xử lý như thế nào?
Có 2 cách xử lý:
1. Xóa những dòng có giới tính là Nữ bên excel hoặc SPSS, sau đó chạy thống kê
2. Dùng menu select case như bên dưới đây, lúc đó không cần xóa dữ liệu. Nhưng vẫn chọn được dữ liệu cần thiết
Cách thực hiện select cases trên SPSS
Bước 1: vào menu Data - Select Cases

Bước 2: chọn mục If condition is satisfied, nhấn nút If như hình dưới

Bước 3: trong hộp điều kiện, nhập vào giá trị GIOITINH=1 , xong bấm continue, và bấm OK
( Do quy định giới tính là 1,2 tương ứng với Nam,Nữ)

Như vậy là đã chọn những quan sát thỏa điều kiện xong, để xem kết quả , ta quay lại file dữ liệu và nhận thấy có một số dòng không thoản điều kiện đã bị gạch chéo như hình dưới. Lúc đó SPSS hiểu là khi chạy thống kê sẽ không sử dụng những dòng này.

Ta thực hiện chạy thống kê tần số lại, kết quả cho thấy mục GIỚI TÍNH chỉ còn 86 người Nam, và tương ứng với ĐỘ TUỔI có 63 người có độ tuổi < 25 tuổi, và 23 người có độ tuổi từ 25 đến 35 tuổi.

Như vậy ta đã dùng chức năng select cases để lựa chọn những dữ liệu cần thiết để thực hiện việc thống kê. Lưu ý là các bạn nhớ bỏ chọn select case bằng cách chọn lại tất cả các cases(Vào menu Data - Select Cases- Chọn All cases - xong bấm OK) khi không có nhu cầu sử dụng lọc dữ liệu, hoặc đơn giản nhất là tắt file spss mở lại là dữ liệu sẽ được chọn tất cả như ban đầu nhé
Các bạn có thể nhờ nhóm hỗ trợ thêm về các vấn đề trong bài luận văn về mã hóa, xử lý số liệu tốt nhé…
Liên hệ nhóm thạc sĩ Hỗ trợ SPSS.
– SMS, Zalo, Viber:
– Chat Facebook: http://facebook.com/hoidapSPSS/
– Email: hotrospss@gmail.com
Cách xuất spss ra word, xuất spss ra excel
Cách xuất kết quả SPSS sang WORD
Cách 1: copy từng bảng và dán vào word


Cách 2: xuất toàn bộ 1 lần kết quả ra file word

- Mục Objects to Export, chọn All visible
- Mục Type,chọn loại là Word/RTF(*.doc) để có thể xuất từ SPSS sang word. Trường hợp muốn xuất từ SPSS sang pdf hoặc sang powerpoint thì cứ việc chọn ở đây là được
- Mục File name, bấm vào Browse để chọn chỗ cần lưu file và tên file xuất từ SPSS
- Sau đó nhấn OK


Cách xuất dữ liệu từ SPSS sang EXCEL


Cách mở file SPSS, cách lưu file SPSS, cách nhập dữ liệu từ excel vào SPSS
Nhóm MBA giới thiệu các thao tác cơ bản trong SPSS như là Cách mở file SPSS, cách lưu file SPSS, cách nhập dữ liệu từ excel vào SPSS
Các dạng file SPSS, SPSS có hai dạng file

- Dạng thứ nhất là file dữ liệu với định dạng là .sav
- Dạng thứ hai là file kết quả với định dạng là .spv
Cách mở file SPSS
Do có hai dạng file, cách mở file SPSS cũng tương ứng với hai loại file này.
Cách mở file dữ liệu SPSS .sav
Ta bật SPSS lên, sau đó vào menu File-Open-Data

Sau đó chọn file sav cần mở và bấm Open.

Lúc đó kết quả hiện lên như sau, đã mở thành công

Cách mở file kết quả SPSS .spv
File spv là file kết quả của SPSS sau khi ta đã thực hiện chạy các phép thống kê, kiểm định
Đầu tiên ta bật SPSS lên và vào File-Open-Output

Chọn file kết quả spv cần mở, sau đó nhấn Open

Kết quả sau đó sẽ hiện lên, các bạn muốn copy vào word phần kết quả nào thì chỉ việc bấm chuột phải vào đó, chọn copy xong dán vào word thôi nhé.

Cách nhập dữ liệu từ excel vào SPSS
Ngoài ra, một việc quan trọng nữa là nhập import data từ excel vào SPSS để chạy. Các bước làm như sau:
Chuẩn bị file excel chuẩn: file excel phải được mã hóa tên biến, dòng đầu tiên là các tên biến, các dòng tiếp theo là người trả lời tương ứng

Sau đó, để đưa import dữ liệu từ Excel vào SPSS, ta bật SPSS lên và sau đó vào menu File-Open-Data
Sau đó chỗ mục Files of Type:, chọn loại là Excel như trong hình.

Sau đó nhấn Open, cửa sổ sau hiện ra, ta chọn tiếp OK.

Thế là ta đã đưa dữ liệu thành công từ excel vào SPSS.

Video cách mở file SPSS, cách lưu file SPSS, cách nhập dữ liệu từ excel vào SPSS:
[embed]https://youtu.be/oEHtbJJ-lPo[/embed]
Như vậy, nhóm MBA Bách Khoa đã giới thiệu các thao tác cơ bản nhất cho người bắt đầu học SPSS về Cách mở file SPSS, cách lưu file SPSS, cách nhập dữ liệu từ excel vào SPSS. Các bạn có thể nhờ nhóm hỗ trợ thêm về các vấn đề trong bài luận văn về mã hóa, xử lý số liệu tốt nhé...
Liên hệ nhóm thạc sĩ Hỗ trợ SPSS.
– SMS, Zalo, Viber:
– Chat Facebook: http://facebook.com/hoidapSPSS/
– Email: hotrospss@gmail.com
Tổng hợp hơn 20 câu hỏi bảo vệ luận văn thạc sỹ sử dụng SPSS thường gặp
Với kinh nghiệm tham gia nhiều buổi bảo vệ luận văn thạc sỹ kinh tế, đồng thời trao đổi với các bạn học viên sau khi các bạn đã bảo vệ thành công. Nhóm MBA ĐH Bách Khoa Hỗ Trợ SPSS giới thiệu đến các bạn Tổng hợp hơn 20 câu hỏi bảo vệ luận văn thạc sỹ sử dụng SPSS, hội đồng hay đề cập các câu này khi bảo vệ luận văn liên quan đến các mô hình kinh tế lượng sử dụng SPSS để giải quyết.
Lưu ý quan trọng khi bảo vệ luận văn: Các bạn nên đi sớm, hoặc đi tham dự các buổi bảo vệ trước để quen không khí và quy trình trong phòng bảo vệ luận văn nhé. Đồng thời thu thập thêm các câu hỏi bảo vệ luận văn( các buổi bảo vệ thường mở cửa tự do cho các học viên khác tham dự)
Các câu hỏi ở đây được đặt theo thứ tự logic của quy trình làm bài làm nhé:
1. Tìm cơ sở lý thuyết
2. Xây dựng mô hình
3. Thiết kế thang đo
4. Nghiên cứu định tính
5. Lập questionaire & thực hiện khảo sát sơ bộ( đa số bài không làm bước này)
6. Lập questionaire & thực hiện khảo sát chính thức
7. Thống kê mô tả
8. Thống kê tần số
9. Kiểm định độ tin cậy cronbach’s alpha
10. Phân tích nhân tố EFA
11. Phân tích tương quan
12. Phân tích hồi quy
13. Phân tích anova, t test
Chi tiết các câu hỏi bảo vệ luận văn thạc sỹ
Các câu hỏi phản biện luận văn liên quan đến đề tài, mô hình...
Câu hỏi bảo vệ luận văn: Tính mới của đề tài này là gì?
-Nếu đề tài của bạn có thể không mới, mô hình không mới, nhưng áp dụng trong một hoàn cảnh nghiên cứu khác, cho một đối tượng khác, trong một không gian địa lý khác, nên đó là tính mới của đề tài.
- Nếu mô hình đề xuất cho đề tài của bạn trước giờ chưa ai làm thì đúng là mới thật, thì bạn phải bảo vệ mô hình này bằng cách nói lên sự cấp thiết, về sự cấp bách của vấn đề cần nghiên cứu, vì chưa ai nghiên cứu nó nên tôi quyết định nghiên cứu.
Câu hỏi bảo vệ luận văn: Bạn tìm cơ sở lý thuyết ở đâu?
Tìm trong các luận văn của các anh chị khóa trước ở thư viện, tìm trên google scholar, ở sciencedirect.com...
Câu hỏi bảo vệ luận văn: Dựa vào đâu để đưa ra mô hình nghiên cứu?
Mô hình nghiên cứu được đưa ra dựa vào các mô hình nghiên cứu trước đây. Cùng với đề xuất của bản thân tác giả( lưu ý là mô hình ví dụ có 7 giả thiết, thì ít nhất đã có 5 giả thiết đã được đặt ra trong các nghiên cứu trước, hạn chế tự đặt giả thiết mà trước giờ chưa ai làm)
Câu hỏi bảo vệ luận văn: Thiết kế thang đo dựa trên cơ sở nào?
Thiết kế thang đo dựa trên cơ sở mô hình nghiên cứu đề xuất. Tuy nhiên không nhất thiết phải làm rập khuông thang đo theo các nghiên cứu trước, mà thường là có thay đổi, cải tiến cho hợp với đề tài.
Câu hỏi bảo vệ luận văn: Nghiên cứu định tính dùng để làm gì?
Nghiên cứu định tính nhằm khám phá, điều chỉnh và bổ sung các biến quan sát dùng để đo lường các khái niệm trong mô hình. Từ đó, các thang đo sơ bộ khái niệm được điều chỉnh phù hợp. Thông tin có được từ thảo luận sẽ được tổng hợp và là cơ sở cho việc hiệu chỉnh, bổ sung các biến trong thang đo. Kỹ thuật là thảo luận tay đôi và diễn dịch.
Câu hỏi bảo vệ luận văn: Lập questionaire & thực hiện khảo sát sơ bộ( đa số bài không làm bước này) để làm gì?
Để hiệu chỉnh bảng câu hỏi chính thức, trong khảo sát sơ bộ sẽ chạy cronbach's alpha. Câu nào bị loại sẽ không được đưa vào nghiên cứu chính thức.
Câu hỏi bảo vệ luận văn: Cơ sở nào để tính số lượng mẫu nghiên cứu của đề tài?
Kích thước mẫu tối thiểu là gấp 5 lần tổng số biến quan sát, các bạn xem chi tiết công thức ở đây nhé: http://phantichspss.com/cong-thuc-xac-dinh-co-mau-bao-nhieu-la-phu-hop-cho-nghien-cuu-2.html
Các câu hỏi phản biện luận văn liên quan đến kĩ thuật sử dụng SPSS...
Câu hỏi bảo vệ luận văn: Thống kê mô tả dùng để làm gì?
Thống kê mô tả dùng cho mục đích thống kê giá trị bé nhất, lớn nhất,trung bình cộng. Ngoài ra còn thống kê được các chỉ tiêu khác nhưng ít xài: Std. Deviation, Variance, Skewness, Kurtosis (chi tiết tại: http://phantichspss.com/huong-dan-cach-chay-thong-ke-mo-ta-trong-spss.html)
Câu hỏi bảo vệ luận văn: Thống kê tần số dùng làm gì?
Dùng để tần suất xuất hiện của các biến định tính, ví dụ: giới tính, trình độ, tuổi tác, học vấn, nghề nghiệp, thu nhập…Thống kê tần số để xác định số lần xuất hiện của một giá trị cụ thể, đồng thời cho ra số tỷ lệ phần trăm tương ứng. (chi tiết tại: http://phantichspss.com/huong-dan-cach-chay-thong-ke-tan-so-trong-spss.html)
Câu hỏi bảo vệ luận văn: Hệ số tin cậy cronbach’s alpha phản ảnh điều gì?
Hệ số tin cậy Cronbach’s Alpha phản ảnh độ tin cậy của thang đo, cho biết các biến đo lường có liên kết với nhau hay không. Hệ số này càng cao càng tốt. Ngưỡng chấp nhận là hệ số này phải lớn hơn 0.6
Câu hỏi bảo vệ luận văn: Khi Cronbach's Alpha if Item Deleted > Cronbach's Alpha thì có loại biến không?
Tùy vào tình huống, nếu giá trị lớn hơn đó không nhiều và nhân tố có ít biến( 3-4-5 biến chẳng hạn) thì lý luận để giữ lại luôn.
Câu hỏi bảo vệ luận văn: Tại sao phải phân tích nhân tố EFA?
Vì mô hình đề xuất là mô hình ban đầu, ứng với các nghiên cứu khác. Còn trường hợp nghiên cứu của mình chưa chắc dữ liệu đã phù hợp với mô hình. Ví dụ mô hình đề xuất có 7 nhân tố độc lập 1 nhân tố phụ thuộc. Khi chạy EFA ra chỉ còn 6 nhân tố độc lập. Như vậy mô hình nghiên cứu mô hình ban đầu cần phải hiệu chỉnh lại. Chỉ có bước EFA mới xác định được vấn đề này. Nói chung mục đích chính của EFA là xác định số lượng nhóm nhân tố thực sự tương ứng với bộ dữ liệu của chúng ta.
Câu hỏi bảo vệ luận văn: Eigenvalues có ý nghĩa như thế nào?
Thông số Eigenvalues (đại diện cho phần biến thiên được giải thích bởi mỗi nhân tố) có giá trị > 1
Câu hỏi bảo vệ luận văn: Hệ số tải Factor Loading trong EFA có ý nghĩa gì?
Tiêu chuẩn đối với hệ số tải nhân tố là phải lớn hơn hoặc bằng 0,5 để đảm bảo mức ý nghĩa thiết thực của EFA. Lúc đó là điều kiện cần để nhân tố đạt được giá trị hội tụ.
Câu hỏi bảo vệ luận văn: Giá trị hội tụ và giá trị phân biệt trong phân tích nhân tố là gì?
Giá trị hội tụ có nghĩa là các biến trong một yếu tố có mối tương quan cao. Điều này được thể hiện bằng các hệ số nhân tố. Hệ số tải phụ thuộc vào kích thước mẫu của bộ dữ liệu của bạn. Nói chung, kích thước mẫu càng nhỏ thì hệ số tải yêu cầu càng cao. Bất kể kích thước mẫu, quy tắc thông dụng tốt nhất là để tải lớn hơn 0.500 .
Giá trị phân biệt: là mức độ mà các yếu tố khác biệt với nhau và không tương quan với nhau. Nguyên tắc là các biến phải liên quan nhiều hơn đến yếu tố của chúng so với các yếu tố khác.
http://phantichspss.com/gia-tri-hoi-tu-va-gia-tri-phan-biet-trong-spss-la-gi.html
Câu hỏi bảo vệ luận văn: Mục đích phân tích tương quan?
Dùng xác định xem có mối tương quan giữa biến độc lập và biến phụ thuộc hay không? Nếu biến độc lập không có tương quan với biến phụ thuộc thì sẽ không đưa biến độc lập vào chạy hồi quy để giải thích cho biến phụ thuộc.
Câu hỏi bảo vệ luận văn: Phân tích hồi quy dùng để làm gì?
Dùng để xác định xem các biến độc lập có thực sự là nguyên nhân giải thích được cho biến phụ thuộc hay không? Đồng thời xác định mức độ giải thích đó là mạnh hay yếu thông qua hệ số R Bình Phương hiệu chỉnh.
Câu hỏi bảo vệ luận văn: R bình phương hiệu chỉnh giải thích gì được cho mô hình?
Giả sử R bình phương hiệu chỉnh là 0.60, thì mô hình hồi quy tuyến tính này phù hợp với tập dữ liệu ở mức 60%. Nói cách khác, 60% biến thiên của biến phụ thuộc được giải thích bởi các biến độc lập.( còn 40% còn lại ở đâu, dĩ nhiên là do sai số đo lường, do cách thu thập dữ liệu, do có thể có biến độc lập khác giải thích cho biến phụ thuộc mà chưa được được vào mô hình nghiên cứu…vv).
http://phantichspss.com/r-binh-phuong-r-binh-phuong-hieu-chinh-cong-thuc-y-nghia-cach-tinh-thu-cong-va-cach-tinh-bang-spss.html
Câu hỏi bảo vệ luận văn: Tại sao r2 chưa hiệu chỉnh >r2 đã hiệu chỉnh?
Vì theo công thức sau:
Vì (n-1)/(n – k) không bao giờ nhỏ hơn 1 nên R2 hiệu chỉnh sẽ không bao giờ lớn hơn R2 .

Câu hỏi bảo vệ luận văn: Tại sao lại lấy hệ số b (hệ số hồi quy chưa chuẩn hóa) để kết luận?
Câu hỏi này rất hay, các bạn lưu ý không phải là chuẩn hóa tốt hơn chưa chuẩn hóa hoặc ngược lại nhé. Mà là mỗi hệ số có cách giải thích riêng của nó:
http://phantichspss.com/so-sanh-su-khac-nhau-giua-he-so-beta-da-chuan-hoa-va-chua-chuan-hoa-khi-phan-tich-hoi-quy.html
Câu hỏi bảo vệ luận văn: Hiện tượng đa cộng tuyến là gì?
Trong mô hình hồi quy, nếu các biến độc lập có quan hệ chặt với nhau, các biến độc lập có mối quan hệ tuyến tính, nghĩa là các biến độc lập có tương quan chặt, mạnh với nhau thì sẽ có hiện tượng đa cộng tuyến, đó là hiện tượng các biến độc lập trong mô hình phụ thuộc lẫn nhau và thể hiện được dưới dạng hàm số. Ví dụ có hai biến độc lập A và B, khi A tăng thì B tăng, A giảm thì B giảm…. thì đó là một dấu hiệu của đa cộng tuyến. Nói một cách khác là hai biến độc lập có quan hệ rất mạnh với nhau, đúng ra hai biến này nó phải là 1 biến nhưng thực tế trong mô hình nhà nghiên cứu lại tách làm 2 biến. Hiện tượng đa cộng tuyến vi phạm giả định của mô hình hồi qui tuyến tính cổ điển là các biến độc lập không có mối quan hệ tuyến tính với nhau.
http://phantichspss.com/da-cong-tuyen-dinh-nghia-cach-phat-hien-hau-qua-cach-khac-phuc.html
Câu hỏi bảo vệ luận văn: Ý nghĩa hệ số Durbin-Watson trong hồi quy?
Dùng để xác định có tương quan bậc 1 ( còn gọi là tự tương quan) giữa các phần dư hay không?
http://phantichspss.com/durbin-watson-thuc-hanh-kiem-dinh-tu-tuong-quan-trong-spss.html
Câu hỏi bảo vệ luận văn: Kiểm định F trong hồi quy có ý nghĩa gì?
Kiểm định F dùng để xác định R bình phương của tổng thể có khác 0 hay không?
Câu hỏi bảo vệ luận văn: Phân tích oneway anova, hoặc independent sample t test dùng để làm gì?
Dùng để xác định xem có sự khác biệt về giá trị trung bình của một biến định lượng( ví dụ SỰ HÀI LÒNG) giữa các nhóm biến định tính khác nhau( ví dụ GIỚI TÍNH). Nghĩa là xem những người giới tính Nam có đánh giá cao sự Hài Lòng hơn so với những người giới tính Nữ hay không?
Câu hỏi bảo vệ luận văn: Sự khác nhau giữa t test và anova là gì?
T test chỉ kiểm định được cho biến có hai nhóm quan sát, còn anova kiểm định được cho biến có từ 2 biến quan sát trở lên, ví dụ 2 3 4 5 nhóm...
http://phantichspss.com/su-khac-nhau-giua-t-test-va-anova.html
Như vậy nhóm MBA Bách Khoa đã giới thiệu hơn 20 câu hỏi bảo vệ luận văn thạc sỹ sử dụng SPSS thường gặp. Các bạn khi thực hiện có thắc mắc, cần hỗ trợ tư vấn xử lý số liệu cứ liên hệ nhóm nhé.
Liên hệ nhóm thạc sĩ Hỗ trợ SPSS.
– SMS, Zalo, Viber:
– Chat Facebook: http://facebook.com/hoidapSPSS/
– Email: hotrospss@gmail.com
Chỉ số Odds ratio – OR và Confidence Interval – CI: định nghĩa, ý nghĩa và cách tính toán
Nhóm MBA hotrospss@gmail.com ĐH Bách Khoa giới thiệu chi tiết về các khái niệm và cách tính các chỉ số Odd , tỉ số Odds ratio - viết tắt là OR, 95% CI Confidence Interval.
Kèm theo ví dụ minh họa cụ thể.
Mục đích:
Ví dụ minh họa: ta có 100 học sinh, trong đó có học thêm 56 em, không học thêm 44 em. Đồng thời ta cũng thống kê được kết quả thi đậu hoặc thi rớt đại học của 100 em này, có 49 em thi rớt và 51 em thi đậu, như trong bảng sau:
Bài này sẽ làm các việc sau:
-Định nghĩa Odd, Odds Ratio,95% CI Confidence Interval. Và tính toán bằng tay để ra được các chỉ số:
-Tính chỉ số Odd thi rớt của nhóm có học thêm
-Tính chỉ số Odd thi rớt của nhóm không học thêm
-Tính Odds Ratio, và so với số 1 để biết được có cần đi học thêm để không thi rớt hay không? Thi rớt đại học có liên quan đến việc học thêm hay không học thêm hay không?
-Tính 95% CI, gồm: khoảng dưới L95 và khoảng trên H95 để biết được khi lặp lại các lần đo lường thì 95% các trường hợp OR sẽ nằm trong giới hạn nào.
-Và cuối cùng là dùng phần mềm SPSS để tính toán các giá trị vừa tính thủ công ở trên để kiểm ra lại cho chắc nhé.

Vậy Odd là gì?
Odd của một biến cố là tỉ số giữa số lần biến cố đó xảy ra và số lần biến cố đó không xảy ra.
Gọi:
O1: là Odd thi rớt của nhóm có học thêm
O2: là Odd thi rớt của nhóm không học thêm
Ta có O1=a/b=4/40=0.1
O2=c/d=45/11=4.09

Odds Ratio là gì?
Chỉ số Odds Ratio OR, chính là tỉ số hai Odd, được biểu diễn là OR =O1/O2 =0.1/4.09=0.024
Ý nghĩa của chỉ số OR:
OR=1: đi học thêm và không đi học thêm có khả năng đậu như nhau
OR>1: nghĩa là Odd thi rớt của nhóm có học thêm CAO HƠN Odd thi rớt của nhóm không học thêm. Có nghĩa là học thêm có hại
OR<1: Học thêm có lợi. Nghĩa là Odd thi rớt của nhóm có học thêm THẤP HƠN Odd thi rớt của nhóm không học thêm.
Như trong trường hợp này, OR=0.024<1 , chứ tỏ học thêm có lợi, làm cho việc thi đậu dễ dàng hơn. Đã trả lời được cho câu hỏi nghiên cứu:Học thêm có giảm nguy cơ thi rớt?
Vậy khoảng tin cậy 95% CI Confidence Interval là gì?
Vấn đề đặt ra: OR có thể khác khi lặp lại nghiên cứu cho những đối tượng khác, giả sử ta lặp lại 100 lần, và trong đó có 97 lần OR<1 thì đây là một bằng chứng chứng cứ khoa học cho thấy học thêm có lợi. Vậy làm sao ta ước lượng được khoảng tin cậy 95% OR?
Công thức: 95% CI =KHOẢNG TIN CẬY 95% OR= TRUNGBÌNH +- 1.96* ĐỘ LỆCH CHUẨN
Với ĐỘ LỆCH CHUẨN= CĂN BẬC 2 CỦA PHƯƠNG SAI
VẤN ĐỀ: rất khó ước lượng Phương Sai của OR vì đây là 1 tỉ số.
Giải pháp, sẽ ước lượng gián tiếp qua 4 bước như sau:
1.Tính Ln(OR)
2.Tính phương sai và độ lệch chuẩn của ln(OR)
3.Tính khoảng tin cậy 95% của ln(OR)
4.Hoán chuyển khoảng tin cậy 95% của ln(OR) thành khoảng tin cậy 95% của OR bằng cách sửa dụng hàm exp()
Cụ thể ví dụ này:
1. Tính Ln(OR) = ln(0.024)=-3.711
2. Tính phương sai và độ lệch chuẩn của ln(OR)
Do OR=O1/O2 , nên đặt: L=ln(OR)=ln(O1/O2)=ln(O1)-ln(O2)=ln(a/b)-ln(c/d)
Công thức toán học về phương sai của L chính là = 1/a+1/b+1/c+1/d = 1/4+1/40+1/45+1/11=0.388
Độ lệch chuẩn của L = căn bậc 2 của(0.388)=0.623
3.Tính khoảng tin cậy 95% của ln(OR)
Khoảng dưới:L-1.96*ĐỘ LỆCH CHUẨN=-3.711 -1.96*0.623=-4.932
Khoảng trên :L+1.96*ĐỘ LỆCH CHUẨN=-3.711 +1.96*0.623=-2.490
4.Hoán chuyển khoảng tin cậy 95% của ln(OR) thành khoảng tin cậy 95% của OR bằng cách sửa dụng hàm exp()
Khoảng dưới L95:=exp(-4.932)=0.007
Khoảng trên H95 :=exp(-2.490)=0.083
Ý nghĩa của OR và khoảng tin cậy 95% CI Confidence Interval:
Ví dụ chỉ số OR = 0.0244: nghĩa là Odd thi rớt của nhóm có học thêm bằng 2.44% Odd thi rớt của nhóm không học thêm
Và nếu lặp lại nghiên cứu này 100 lần thì 95% các số OR sẽ dao động từ L95 đến H95, nghĩa là dao động từ 0.007 đến 0.083
File dữ liệu thực hành để tính OR
Ngoài OR Odds Ratio và khoảng tin cậy 95% CI cũng có thể được tính bằng phần mềm SPSS, file dữ liệu của bài này các bạn tải ở đây http://phantichspss.com/filefordownload/Odds-Ratio-95-CI.sav
Khi chạy ra kết quả y hệt phần tính bằng tay như hình sau:
Phần màu xanh là chỉ số Odds Ratio, còn 2 giá trị màu đỏ là mức dưới và trên của 95% Confidence Interval
Như vậy nhóm MBA Bách Khoa đã hướng dẫn chi tiết về các khái niệm và cách tính các chỉ số Odd , tỉ số Odds ratio , 95% CI Confidence Interval. Các bạn khi thực hiện có thắc mắc, cần giải giúp bài tập hoặc cần hỗ trợ xử lý số liệu cho ổn hơn cứ liên hệ nhóm nhé.

Liên hệ nhóm thạc sĩ Hỗ trợ SPSS.
– SMS, Zalo, Viber:
– Chat Facebook: http://facebook.com/hoidapSPSS/
– Email: hotrospss@gmail.com
Phân tích hồi quy đa thức Multinomial logistic regression bằng SPSS
Nhóm Thạc Sĩ QTKD ĐH Bách Khoa giới thiệu về lý thuyết và cách thực hành, cách phân tích ý nghĩa kết quả hồi quy đa thức. Kèm theo file dữ liệu thực hành luôn nhé.
Lý thuyết hồi quy đa thức
Mô hình hồi quy đa thức, còn gọi là hồi quy logistic đa thức (Multinomial logistic regression) tương tự như mô hình hồi quy logistic nhị phân nhưng biến phụ thuộc là biến định tính có nhiều hơn 2 trạng thái.
Ví dụ: dùng hồi quy đa thức để xác định loại nước uống nào được thích hơn. Biến phụ thuộc : loại nước uống ( gồm 3 loại: Cafe, nước giải khát có gas Soft drink , trà và nước lọc), biến độc lập là độ tuổi( là biến liên tục) và vùng miền( là biến phân loại Bắc, Trung, Nam)

Như vậy, biến phụ thuộc là biến phân loại,còn biến độc lập có thể là biến phân loại hoặc là biến liên tục.
Cách thực hành phân tích hồi quy đa thức trên SPSS
Đầu tiên tạo 3 biến trong SPSS như sau:
- Biến độc lập độ tuổi, là biến liên tục, ví dụ 30,31,32 tuổi.
- Biến độc lập vùng miền, là biến phân loại: Nam, Trung, Bắc tương ứng với giá trị mã hóa 0 1 2
- Biến phụ thuộc Loại nước uống yêu thích: Cafe, nước giải khát có gas Soft drink , trà và nước lọc. Tương ứng với mã hóa 0 1 2
Sau đó nhập các giá trị đã khảo sát vào, sẽ được như sau:

Các bạn có thể tải file thực hành hồi quy đa thức ở đây: www.phantichspss.com/filefordownload/phantichspss-hoi-quy-da-thuc.sav
Nhấn vào menu Analyze > Regression > Multinomial Logistic.
Cửa sổ phân tích hồi quy đa thức hiện ra như sau:
Đưa lần lượt các biến vào như sau
- Biến phụ thuộc phân loại "Loại nước uống" Loainuocuong đưa vào ô Dependent.
- Biến độc lập liên tục "Độ tuổi" Tuoi được đưa vào ô Covariate.
- Biến độc lập phân loại "Vùng miền" Vungmien được đưa vào ô Factor(s).
Mặc định, nhóm tham chiếu của biến phụ thuộc là nhóm cuối cùng, ví dụ Loainuocuong(Last) như hình trên.
Nhấn vào nút Statistics, để hiện ra được bảng Multinomial Logistic Regression: Statistics như sau:
Chọn vào 2 checkboxes Classification table và Goodness-of-fit . Sau đó nhấn Continue
Nhấn nút OK để bắt đầu hiển thị kết quả phân tích hồi quy đa thức.




Cách đọc kết quả phân tích hồi quy đa thức trên SPSS
Bảng Goodness-of-Fit giả thích độ phù hợp của dữ liệu so với mô hình.
Dòng đầu tiên Pearson thể hiện kiểm định chi-square. Giá trị chi-square càng lớn thì mô hình càng kém phù hợp. Nếu sig.<5% thì chắc chắn là mô hình không phù hợp với dữ liệu này. Ở đây ta thấy sig=0.110 >5% nên mô hình này phù hợp với dữ liệu.

Bảng Model Fitting Information
Dòng "Final" thể hiện có phải tất cả các hệ số trong mô hình bằng 0 hay không? Hiểu theo cách khác là nếu mô hình này có biến độc lập được thêm vào thì có tốt hơn là mô hình chỉ có hệ số chặn intercept hay không( mô hình không có biến độc lập). Ở đây giá trị sig.=0.00 < 5% nên ta kết luận mô hình với đầy đủ các biến độc lập dự đoán biến phụ thuộc tốt hơn so với mô hình chỉ có hệ số chặn intercept.

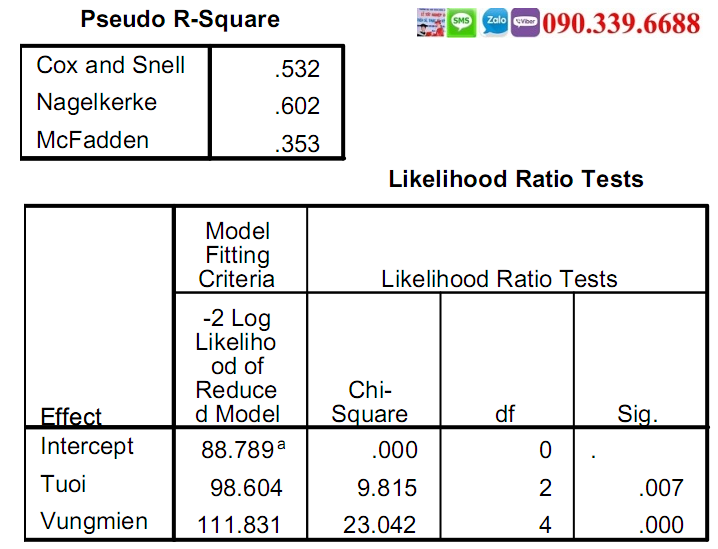
Bảng Pseudo R-Square và bảng Likelihood Ratio Tests
Trị số R bình phương giả pseudo-R2 gần như tương tự với R bình phương trong hồi quy tuyến tính.
Còn bảng Likelihood Ratio Tests cho ta thấy các biến độc lập có tác động có ý nghĩa thống kê đến biến phụ thuộc hay không? Nếu cột Sig.<0.05 thì biến độc lập đó có tác động. Thật ra bảng này chỉ hữu ích khi đánh giá cho biến phân loại, vì đây là bảng duy nhất cho thấy tác động chung của biến phân loại. Còn phân tích chi tiết như bảng Parameter Estimates dưới đây thì không thấy được tác động chung của biến độc lập phân loại ( ở đây là biến Vùng miền)
Bảng Parameter Estimates dùng để đánh giá các giả thiết có được chấp nhận hay không?
Về ý tưởng, bảng này là kết quả so sánh giữa nhóm Cafe, và nước có gas Soft Drink với nhóm tham chiếu cơ sở là Tea & Water. Việc chọn nhóm tham chiếu cơ sở nào là do mình tự quyết định( có thể làm lúc chọn biến phụ thuộc đưa vào ô Dependent, sau đó nhấn nút Reference Category để chọn nhóm cơ sở).

Phân tích so sánh giữa nhóm tham chiếu Tea & Water và nhóm Cafe:
-Dòng "Tuoi", có sig=0.003 <5%, nên biến Tuoi có ý nghĩa thống kê, hệ số B = -0.251 nên khi tuổi tăng thì sự dịch chuyển từ Tea & Water đến Cafe giảm. Nghĩa là tuổi tăng thì người ta thích uống Tea & Water hơn là Cafe. Cụ thể giá trị B = -0.251 ý nghĩa là log(odds) giảm được 0.251 khi tuổi tăng 1 đơn vị. Còn hệ số exp(B) = exp(-0.251)= 0.778 có ý nghĩa là chỉ số odds của một người 31 tuổi gấp 0.778 lần so với người 30 tuổi, giả định mọi chỉ số khác đều bằng nhau.
- Dòng Vungmien=1 có sig.=0.039<5% nên biến Vùng miền=1 so với Vùng miền =2 có ý nghĩa thống kê. Hệ số B=1.890 nên khi vùng miền chuyển từ vùng 2( miền Bắc) sang vùng 1( miền Trung) thì sự dịch chuyển từ Tea & Water đến Cafe tăng. Nghĩa là người miền Trung ưa thích Cafe hơn là Tea & Water so với người miền Bắc.
- Do dòng Vungmien=0 có sig.=0.077>5% nên biến Vùng miền=0 so với Vùng miền =2 không có ý nghĩa thống kê.

Tương tự , ta phân tích so sánh giữa nhóm tham chiếu Tea & Water và nhóm Soft drink.
Còn việc cần so sánh giữa nhóm Cafe vào Soft drink thì sao? Lúc này ta cần thực hiện chạy hồi quy đa thức lại, với nhóm tham chiếu là nhóm Cafe. Lúc đó chương trình sẽ chạy ra lấy nhóm Cafe so với nhóm Tea & Water . Và nhóm Cafe so với nhóm Soft Drink. Việc chọn nhóm tham chiếu bằng cách nhấn nút Reference Category và điền vào số mình cần làm tham chiếu như trong hình.
Như vậy nhóm MBA Bách Khoa đã hướng dẫn phần thực hành chạy và đọc ý nghĩa phân tích hồi quy đa thức. Các bạn khi thực hiện có thắc mắc hoặc cần hỗ trợ xử lý số liệu cho ổn hơn cứ liên hệ nhóm nhé.
Chúc các bạn làm tốt.