Nhóm Thạc Sĩ QTKD ĐH Bách Khoa giới thiệu về lý thuyết và cách thực hành, cách phân tích ý nghĩa kết quả hồi quy đa thức. Kèm theo file dữ liệu thực hành luôn nhé.
Lý thuyết hồi quy đa thức
Mô hình hồi quy đa thức, còn gọi là hồi quy logistic đa thức (Multinomial logistic regression) tương tự như mô hình hồi quy logistic nhị phân nhưng biến phụ thuộc là biến định tính có nhiều hơn 2 trạng thái.
Ví dụ: dùng hồi quy đa thức để xác định loại nước uống nào được thích hơn. Biến phụ thuộc : loại nước uống ( gồm 3 loại: Cafe, nước giải khát có gas Soft drink , trà và nước lọc), biến độc lập là độ tuổi( là biến liên tục) và vùng miền( là biến phân loại Bắc, Trung, Nam)

Như vậy, biến phụ thuộc là biến phân loại,còn biến độc lập có thể là biến phân loại hoặc là biến liên tục.
Cách thực hành phân tích hồi quy đa thức trên SPSS
Đầu tiên tạo 3 biến trong SPSS như sau:
- Biến độc lập độ tuổi, là biến liên tục, ví dụ 30,31,32 tuổi.
- Biến độc lập vùng miền, là biến phân loại: Nam, Trung, Bắc tương ứng với giá trị mã hóa 0 1 2
- Biến phụ thuộc Loại nước uống yêu thích: Cafe, nước giải khát có gas Soft drink , trà và nước lọc. Tương ứng với mã hóa 0 1 2
Sau đó nhập các giá trị đã khảo sát vào, sẽ được như sau:

Các bạn có thể tải file thực hành hồi quy đa thức ở đây: www.phantichspss.com/filefordownload/phantichspss-hoi-quy-da-thuc.sav
Nhấn vào menu Analyze > Regression > Multinomial Logistic.
Cửa sổ phân tích hồi quy đa thức hiện ra như sau:
Đưa lần lượt các biến vào như sau
- Biến phụ thuộc phân loại "Loại nước uống" Loainuocuong đưa vào ô Dependent.
- Biến độc lập liên tục "Độ tuổi" Tuoi được đưa vào ô Covariate.
- Biến độc lập phân loại "Vùng miền" Vungmien được đưa vào ô Factor(s).
Mặc định, nhóm tham chiếu của biến phụ thuộc là nhóm cuối cùng, ví dụ Loainuocuong(Last) như hình trên.
Nhấn vào nút Statistics, để hiện ra được bảng Multinomial Logistic Regression: Statistics như sau:
Chọn vào 2 checkboxes Classification table và Goodness-of-fit . Sau đó nhấn Continue
Nhấn nút OK để bắt đầu hiển thị kết quả phân tích hồi quy đa thức.




Cách đọc kết quả phân tích hồi quy đa thức trên SPSS
Bảng Goodness-of-Fit giả thích độ phù hợp của dữ liệu so với mô hình.
Dòng đầu tiên Pearson thể hiện kiểm định chi-square. Giá trị chi-square càng lớn thì mô hình càng kém phù hợp. Nếu sig.<5% thì chắc chắn là mô hình không phù hợp với dữ liệu này. Ở đây ta thấy sig=0.110 >5% nên mô hình này phù hợp với dữ liệu.

Bảng Model Fitting Information
Dòng "Final" thể hiện có phải tất cả các hệ số trong mô hình bằng 0 hay không? Hiểu theo cách khác là nếu mô hình này có biến độc lập được thêm vào thì có tốt hơn là mô hình chỉ có hệ số chặn intercept hay không( mô hình không có biến độc lập). Ở đây giá trị sig.=0.00 < 5% nên ta kết luận mô hình với đầy đủ các biến độc lập dự đoán biến phụ thuộc tốt hơn so với mô hình chỉ có hệ số chặn intercept.

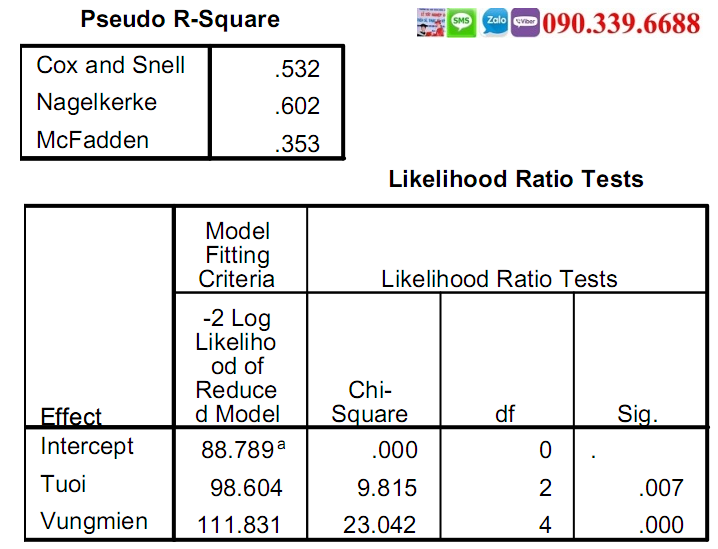
Bảng Pseudo R-Square và bảng Likelihood Ratio Tests
Trị số R bình phương giả pseudo-R2 gần như tương tự với R bình phương trong hồi quy tuyến tính.
Còn bảng Likelihood Ratio Tests cho ta thấy các biến độc lập có tác động có ý nghĩa thống kê đến biến phụ thuộc hay không? Nếu cột Sig.<0.05 thì biến độc lập đó có tác động. Thật ra bảng này chỉ hữu ích khi đánh giá cho biến phân loại, vì đây là bảng duy nhất cho thấy tác động chung của biến phân loại. Còn phân tích chi tiết như bảng Parameter Estimates dưới đây thì không thấy được tác động chung của biến độc lập phân loại ( ở đây là biến Vùng miền)
Bảng Parameter Estimates dùng để đánh giá các giả thiết có được chấp nhận hay không?
Về ý tưởng, bảng này là kết quả so sánh giữa nhóm Cafe, và nước có gas Soft Drink với nhóm tham chiếu cơ sở là Tea & Water. Việc chọn nhóm tham chiếu cơ sở nào là do mình tự quyết định( có thể làm lúc chọn biến phụ thuộc đưa vào ô Dependent, sau đó nhấn nút Reference Category để chọn nhóm cơ sở).

Phân tích so sánh giữa nhóm tham chiếu Tea & Water và nhóm Cafe:
-Dòng "Tuoi", có sig=0.003 <5%, nên biến Tuoi có ý nghĩa thống kê, hệ số B = -0.251 nên khi tuổi tăng thì sự dịch chuyển từ Tea & Water đến Cafe giảm. Nghĩa là tuổi tăng thì người ta thích uống Tea & Water hơn là Cafe. Cụ thể giá trị B = -0.251 ý nghĩa là log(odds) giảm được 0.251 khi tuổi tăng 1 đơn vị. Còn hệ số exp(B) = exp(-0.251)= 0.778 có ý nghĩa là chỉ số odds của một người 31 tuổi gấp 0.778 lần so với người 30 tuổi, giả định mọi chỉ số khác đều bằng nhau.
- Dòng Vungmien=1 có sig.=0.039<5% nên biến Vùng miền=1 so với Vùng miền =2 có ý nghĩa thống kê. Hệ số B=1.890 nên khi vùng miền chuyển từ vùng 2( miền Bắc) sang vùng 1( miền Trung) thì sự dịch chuyển từ Tea & Water đến Cafe tăng. Nghĩa là người miền Trung ưa thích Cafe hơn là Tea & Water so với người miền Bắc.
- Do dòng Vungmien=0 có sig.=0.077>5% nên biến Vùng miền=0 so với Vùng miền =2 không có ý nghĩa thống kê.

Tương tự , ta phân tích so sánh giữa nhóm tham chiếu Tea & Water và nhóm Soft drink.
Còn việc cần so sánh giữa nhóm Cafe vào Soft drink thì sao? Lúc này ta cần thực hiện chạy hồi quy đa thức lại, với nhóm tham chiếu là nhóm Cafe. Lúc đó chương trình sẽ chạy ra lấy nhóm Cafe so với nhóm Tea & Water . Và nhóm Cafe so với nhóm Soft Drink. Việc chọn nhóm tham chiếu bằng cách nhấn nút Reference Category và điền vào số mình cần làm tham chiếu như trong hình.
Như vậy nhóm MBA Bách Khoa đã hướng dẫn phần thực hành chạy và đọc ý nghĩa phân tích hồi quy đa thức. Các bạn khi thực hiện có thắc mắc hoặc cần hỗ trợ xử lý số liệu cho ổn hơn cứ liên hệ nhóm nhé.
Chúc các bạn làm tốt.
Không có nhận xét nào:
Đăng nhận xét